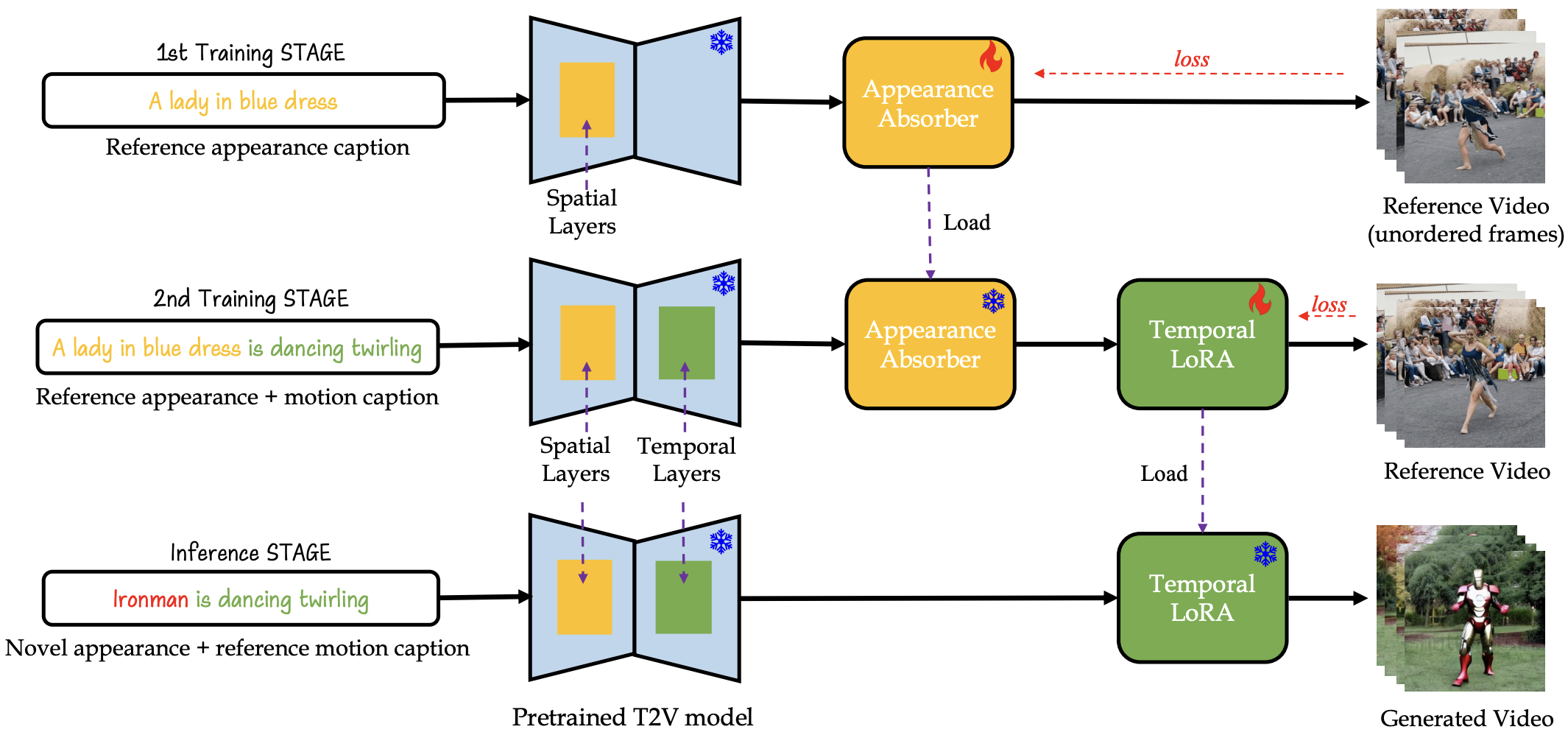
Method
Comparison Results
Applications
DDIM Inverted Latent Input
Customize-A-Video can cooperate with additional control signals to produce precise video editing per frame.
Video Appearance Customization
Customize-A-Video are compatible with image customization modules to customize videos both spatially and temporally.
Multiple Reference Motion Combination
Multiple Customize-A-Video modules can collaborate to generate videos with multiple target motions combined.
Third-Party Appearance Absorbers
Customize-A-Video features a staged training pipeline and thus its Temporal LoRA can be trained with loading third-party appearance absorbers tuned on other image data if they share similar appearances.
Concurrent Work
There's a lot of excellent work that was introduced around the same time as ours.
Customizing Motion in Text-to-Video Diffusion Models finetunes temporal layers in place with special tokens in Dreambooth way.
VMC finetunes temporal layers in place too with a replaced frame residual vector loss.
MotionCrafter employs two parallel UNets and tune one of them with an additional appearance normalization loss.
DreamVideo adds adapters over temporal attentions conditioned on a frame to decompose motion from appearance.
MotionDirector applies dual-path LoRAs on spatial and temporal attentions and trains them jointly with appearance-debiased temporal losses.
BibTeX
@inproceedings{ren2024customize,
title={Customize-a-video: One-shot motion customization of text-to-video diffusion models},
author={Ren, Yixuan and Zhou, Yang and Yang, Jimei and Shi, Jing and Liu, Difan and Liu, Feng and Kwon, Mingi and Shrivastava, Abhinav},
booktitle={European Conference on Computer Vision},
pages={332--349},
year={2024},
organization={Springer}
}