|
Yixuan Ren I obtained my Ph.D. in Computer Science at the University of Maryland, College Park, advised by Prof. Abhinav Shrivastava. I also received my M.S. degree here. Prior to that, I received my B.E. degree from Tsinghua University. My research lies in the intersection of Computer Vision and Generative AI, with focuses on image and video synthesis and editing. I am broadly interested in various generative modeling techniques and visual tokenization for generative purposes. I am actively seeking full-time opportunities. If you think I could be a good fit, please don't hesitate to reach out! Email / Resume / Google Scholar / LinkedIn / Bluesky |

|
Experience
|
 Meta GenAI/MSL, 2025
Meta GenAI/MSL, 2025
Publications* equal contribution † project lead |

|
Direct Evolution of Instructional Image Editing
Yixuan Ren, Mannat Singh†, Saketh Rambhatla, Andrew Brown, Arun Mallya, Abhinav Shrivastava 2026 Flow directly from source to target images for efficient inversion-free instructional image editing. |
|
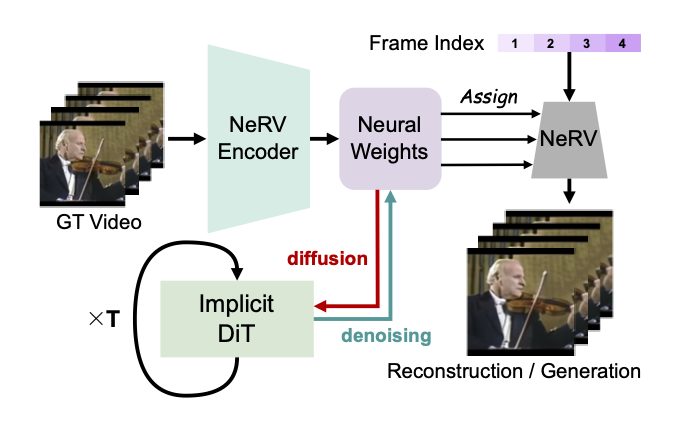
NeRV-Diffusion: Diffuse Implicit Neural Representation for Video Synthesis
Yixuan Ren, Hanyu Wang, Hao Chen, Bo He, Abhinav Shrivastava ICLR, 2026 project page / arxiv Generate network weights via a diffusion model, which parameterize an implicit neural representation and self-decode to synthesize a video. |
|
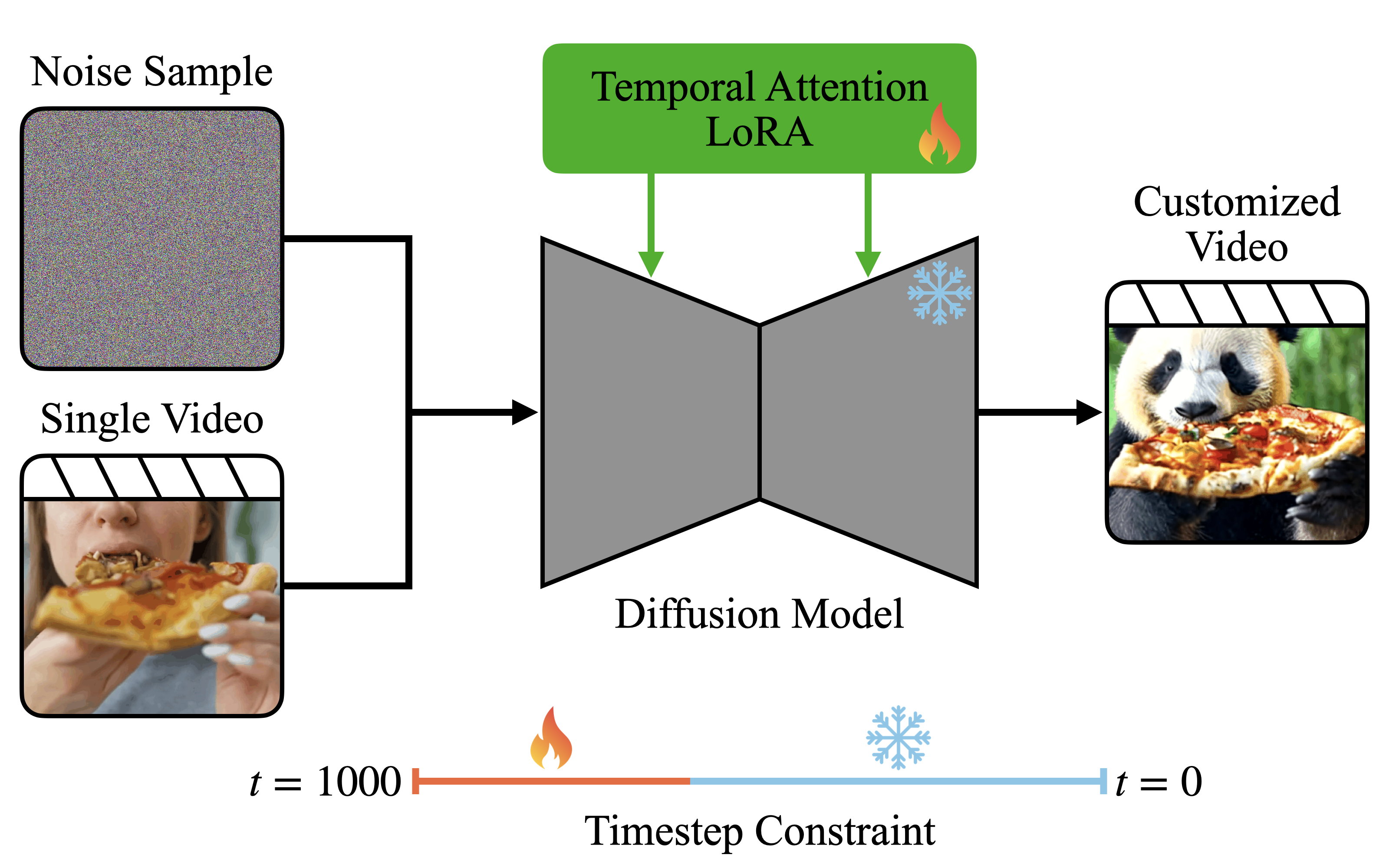
Timestep-Constrained One-Shot Video Motion Customization
Vatsal Baherwani*, Yixuan Ren*†, Abhinav Shrivastava CVPR Workshop, 2026 project page / arxiv Single-stage module-less one-shot video motion customization via constraining within temporal-dominant early denoising timesteps. |
|
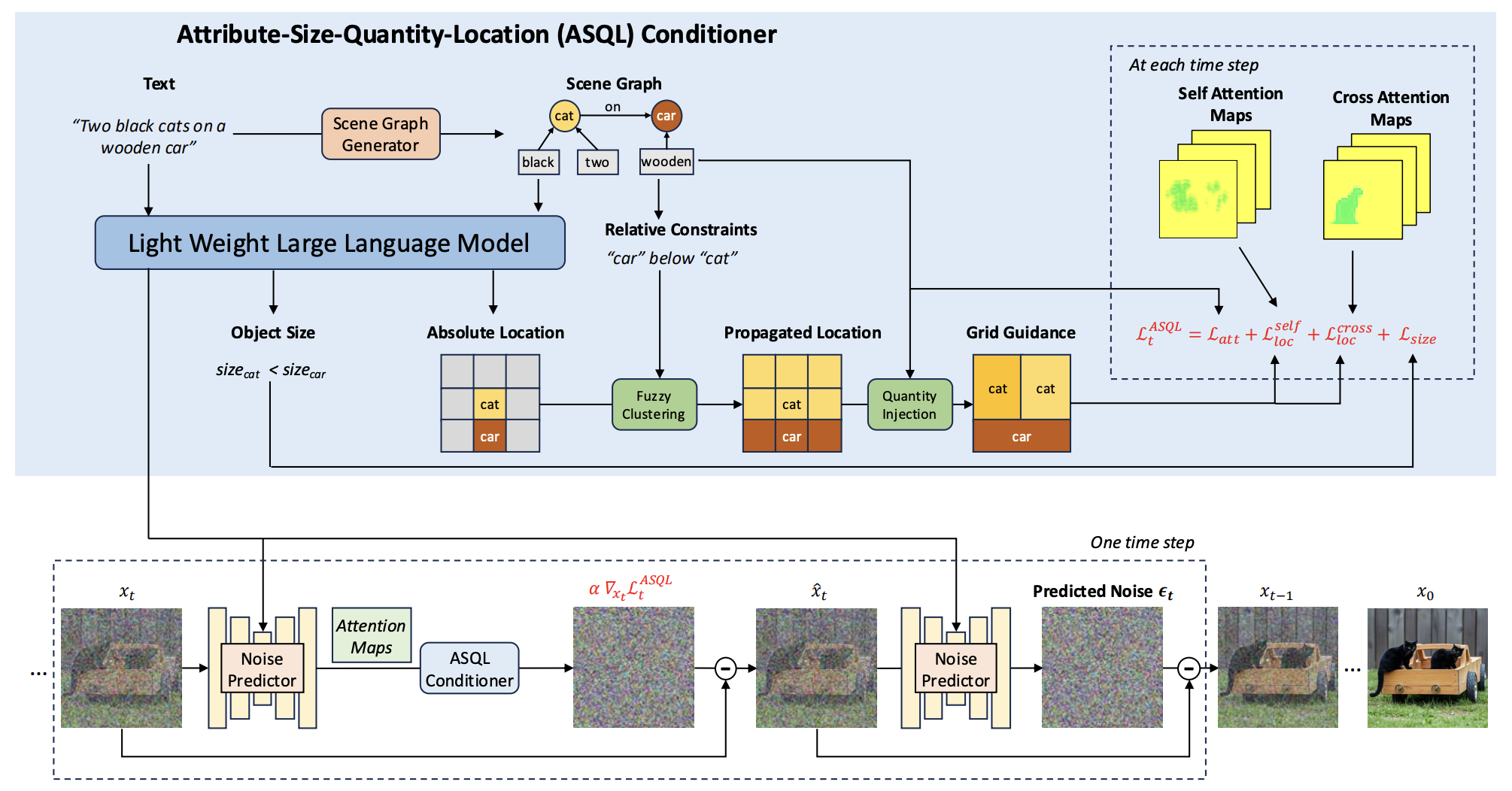
All-in-One Conditioning for Text-to-Image Synthesis
Hirunima Jayasekara, Chuong Huynh†, Yixuan Ren†, Christabel Acquaye, Abhinav Shrivastava ICPR, 2026 arxiv A zero-shot, scene graph-based conditioning mechanism for compositional text-to-image generation with soft visual guidance. |
|
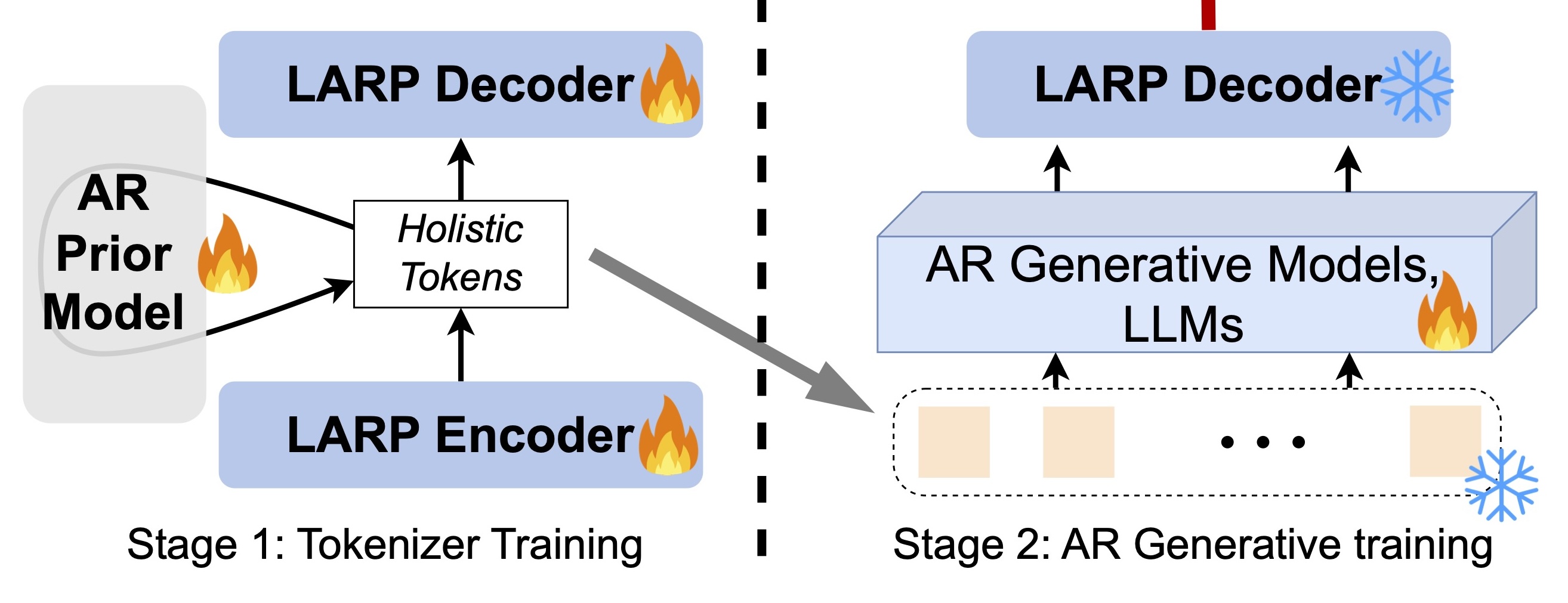
LARP: Tokenizing Videos with a Learned Autoregressive Generative Prior
Hanyu Wang, Saksham Suri, Yixuan Ren, Hao Chen, Abhinav Shrivastava ICLR, 2025 (Oral) project page / arxiv / code A holistic video tokenizer that integrates a light weight autoregressive transformer to align the latent space with AR generative models. |
|
|
Customize-A-Video: One-Shot Motion Customization of Text-to-Video Diffusion Models
Yixuan Ren, Yang Zhou†, Jimei Yang, Jing Shi, Difan Liu, Feng Liu, Mingi Kwon, Abhinav Shrivastava ECCV, 2024 project page / paper / arxiv Customize pre-trained video diffusion models from a single reference video and adapt its motion to new subjects and scenes with temporal diversity. |

|
Content-Adaptive Image Color Editing with Auxiliary Color Restoration Tasks
Yixuan Ren, Jing Shi†, Zhifei Zhang†, Yifei Fan, Zhe Lin, Bo He, Abhinav Shrivastava WACV, 2024 paper / supplementary Edit the color tone of an image with the editing styles spatially adaptive to its content. |
|
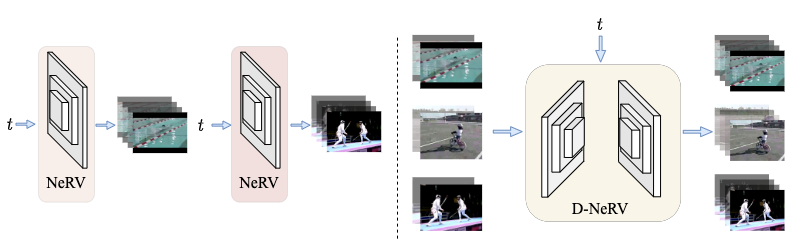
Towards Scalable Neural Representation for Diverse Videos
Bo He, Xitong Yang, Hanyu Wang, Zuxuan Wu, Hao Chen, Shuaiyi Huang, Yixuan Ren, Ser-Nam Lim, Abhinav Shrivastava CVPR, 2023 project page / arxiv / code A video implicit neural representation that encodes large-scale and diverse videos faithfully and efficiently. |
|
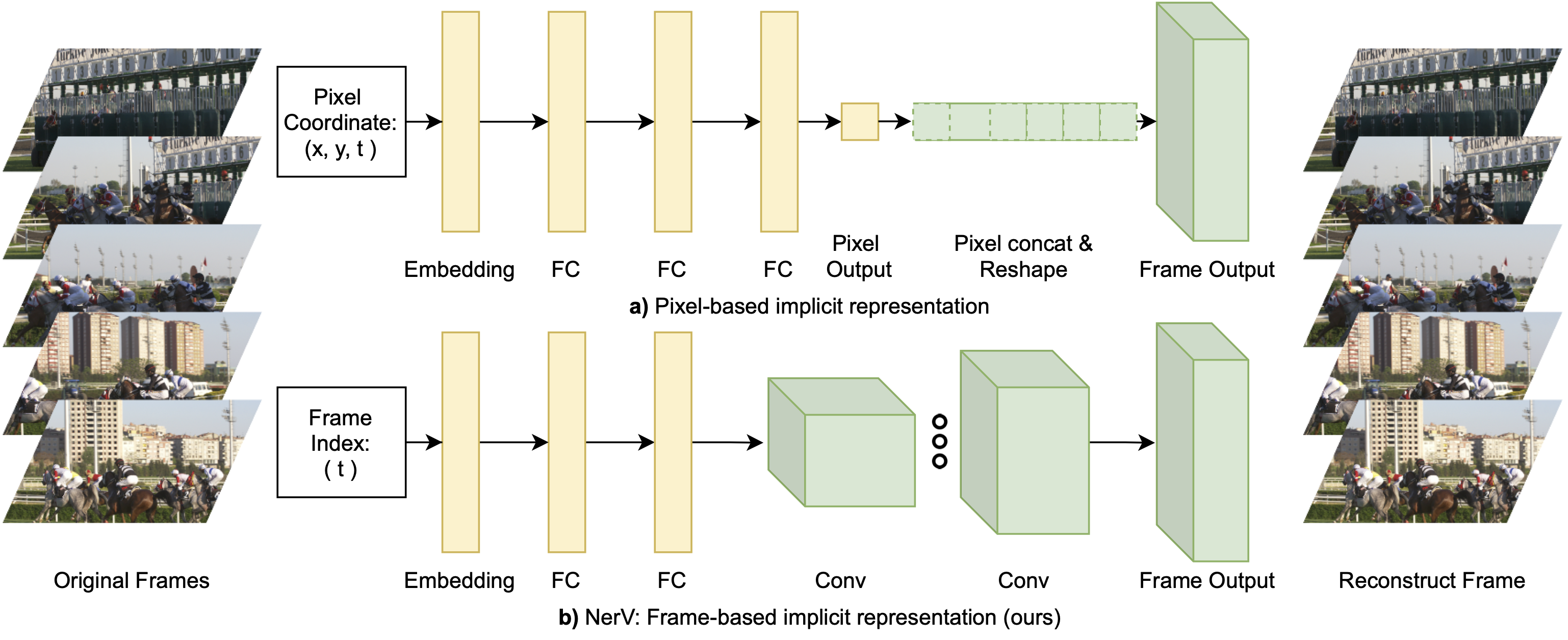
NeRV: Neural Representations for Videos
Hao Chen, Bo He, Hanyu Wang, Yixuan Ren, Ser-Nam Lim, Abhinav Shrivastava NeurIPS, 2021 project page / arxiv / code A frame-wise video implicit neural representation that encodes a video into a dedicated neural network's parameters |
|
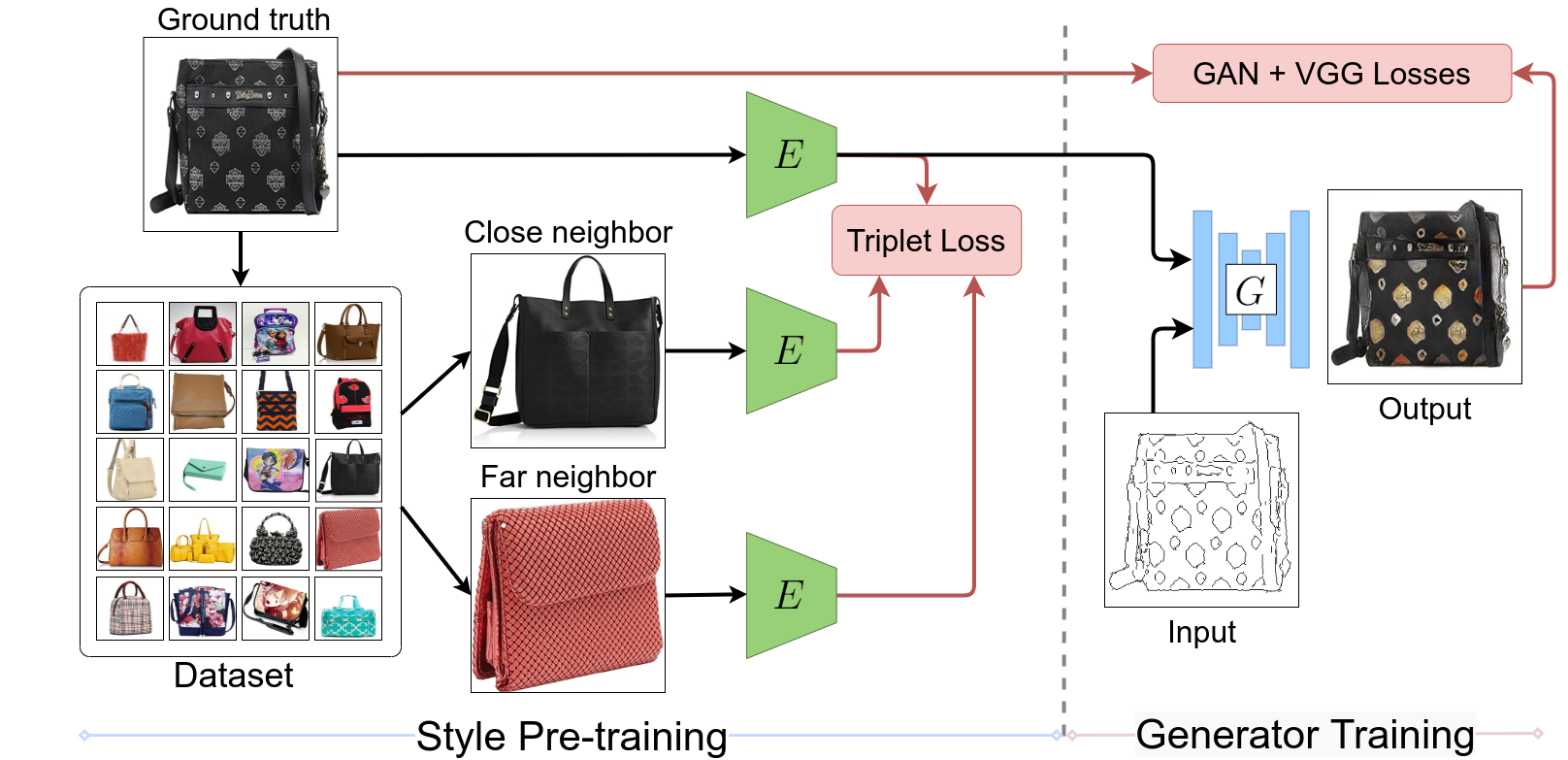
StEP: Style-based Encoder Pre-training for Multi-modal Image Synthesis
Moustafa Meshry, Yixuan Ren, Larry S. Davis, Abhinav Shrivastava CVPR, 2021 project page / paper / arxiv / code A two-stage MMI2I method via style encoder pre-training for simplifed losses and stablized training. |
Services
|
|
Thanks Jon Barron for the template. |